Computational Data Science
CMPT 353, Summer 2026
Greg Baker
This Course
It's Computational Data Science
. We'll come back to what that is.
Course web site: in CourSys, https://coursys.sfu.ca/2026su-cmpt-353-d1/pages/ .
This Course
Whoever you are, I'm glad you're here.



Offering Strategy
My plan is to keep the parts of this course that worked best in-person pre-pandemic, and the parts that worked best online. Basically:
- Lectures by video.
- Hands-on help (office hours, etc) in-person.
- Quizzes in-person.
Offering Strategy
Lectures will be pre-recorded.
In the lecture time, they will be available as a YouTube Premier
(≈ watch party) in ≈50 minute chunks. Greg will be available in YouTube chat to answer questions during that time.
They will be available as regular YouTube videos for viewing later.
Grades
- Weekly exercises: 12 × 3% = 36%
- Quizzes: 3 × 15% = 45%
- Project: 19%
Late penalty: 20%/day on exercises & project.
Exercises
Due Fridays. My goal: make sure you actually try out the things we have talked about and see the reality of applying them.
Will contain some short problems to get you used to the tools, expanding to something a more interesting real
problem.
Project
In the lectures/exercises, I intend to explore what I consider the core
of data science.
The project will let you integrate those techniques and explore other ideas, depending what interests you.
Project
I will post project topic ideas that are intended as starting points for your thinking about a project (not as ready-to-go project topics).
We can discuss project ideas in the lab or discussion forum.
Due date may shift, depending on our final exam date.
Project
A few details:
- Completed individually.
- Take the problem. Use the techniques from the course, and explore others to sensibly attack the problem.
- In a report, summarize your methods, findings, and what worked/didn't.
- Focus on solving a problem, not applying random techniques.
Quizzes
Quizzes: in-person. Dates may change if necessary, but planned during lecture times:
- June 19 (Friday of week 6),
- July 17 (Friday of week 10),
- final exam period (scheduled as a final exam).
All closed book, on paper. Missing/excusing quizzes requires medical documentation.
Quizzes
I have asked for a final exam
time that will be what I think of as Quiz 3
. Thus its timing isn't known yet.
I may adjust the due dates of Exercise 12 and the Project to be reasonable around Quiz 3.
Us
Instructor: Greg Baker <[email protected]>.
Office hour: Wednesdays 12:00–13:00 in CSIL (ASB 9838) and Fridays 2:30–3:30 in CSIL (ASB 9700).
Us
TAs: to be announced.
Office hours: details later.
Us
Greg's honest order of priority when dealing with student queries:
- In-person questions in CSIL, etc.
- Public questions in the discussion forum.
- Anything else that helps >1 student.
- Private questions in the discussion forum.
- Email.
Lectures and Labs
Tuesdays: lectures
premier as scheduled, live chat. Regular YouTube videos after that.
Fridays: usually no lectures
. The TAs and I will all be available for consultation during the lecture time in CSIL (ASB 9700).
References
Textbooks: none.
Possible reference material:
- Python Data Science Handbook [SFU library]. Also on Github. Good overview of Python, Pandas, matplotlib, Scikit-Learn.
- Python for Data Analysis [SFU library]. Intro to data science workflow, focussing on Python tools.
References
Possible reference material (continued):
- Data Science from Scratch [SFU library]. Building data science tools from scratch so you can see the details.
- Think Like a Data Scientist [SFU library]. Overview of approaching data science problems.
- Additional links to be provided on course web site.
Programming
Python 3 will be the primary programming language language used in the course. If you aren't comfortable with it, you need to be (very) soon.
StackExchange Data Science tags (as of April 2025):
| Language | Tagged Qs |
|---|---|
| Python | 6639 |
| R | 1445 |
| Matlab | 150 |
| Java | 55 |
| Scala | 47 |
Programming
This will be a programming-heavy course. If you don't really like programming, this might not be the course for you.
The programming style will be very library-heavy, which is realistic in the modern world. We will use many libraries: NumPy, Pandas, matplotlib, scikit-learn, statsmodels, ….
Programming
That means you should spend a lot of time reading the docs and fighting to make the tools do what you want them to, and less implementing the logic yourself. That's also realistic.
The code you would have written would almost certainly have been slower and worse.
Advice: don't run straight to Google or ChatGPT when you encounter adversity. Use the reference docs. Think.
Programming
I will feel free to increase the amount of assignment work a little from my usual level because of the missing
hour of lecture.
Expectations
To get credit for this course, I expect you to demonstrate that you know how to use programming techniques to manipulate and analyse data. That means:
- A pass on the weighted average of the stuff where you demonstrate programming ability: exercises + project.
- A pass on the weighted average of the quizzes.
Failure to do these may result in failing the course.
Expectations
That rule isn't intended to fail someone just because they get 49% on the quizzes: it will be applied on an individual basis with a judgement call on the question has this student has demonstrated that they understand the basic concepts of the course?
Expectations
Academic Honesty: it's important, as always.
If you're using an online source, leave a comment.
def this_function(p1, p2):
# adapted from http://stackoverflow.com/a/21623206/1236542
...
That's all I ask, but remember to do it.
Expectations
You are expected to do the work in this course yourself. Whenever you submit any work at the University, you're implicitly certifying this is my own independent work
.
Expectations
Examples of things that are not okay and will be treated as academic dishonesty:
- Using a tool (like an LLM) to create some code and cleaning it up a little, or having a tool
fix
your code. - Finding a solution (online or from your friend), looking at it until you really, really understand it, changing enough you think I won't notice the similarity, and submitting it.
- Sitting beside your friend and creating a single solution together, even though you're touching different keyboards.
Expectations
The quizzes are regular tests: individual work, closed book.
For the quizzes, I will consider it academic dishonesty to have any of these in any way available to you (including in your pocket, within arm's length, under your seat, etc): phone, smart watch, smart glasses, smart ring, calculator, fitness tracker, earbuds, smart anything else that can be used to communicate or connect to the internet.
Yes, even if you promise you didn't use it. [If you have a medical device that might fall into that category, let me know before the exam.]
Computational Data Science?
Computational Data Science
: data science, but with computation as the focus.
But what is data science?
Data Science?
According to Wikipedia: an interdisciplinary academic field that uses… [various disciplines] to extract or extrapolate knowledge and insights from… data.
According to Pat Hanrahan, Tableau Software: [The combination of] business knowledge, analytical skills, and computer science.
According to Daniel Tunkelang, LinkedIn: [The ability to] obtain, scrub, explore, model and interpret data, blending hacking, statistics and machine learning.
Data Science?
According to Joel Grus: There's a joke that says a data scientist is someone who knows more statistics than a computer scientist and more computer science than a statistician.… We'll says that a data scientist is someone who extracts insights from messy data.
Data Science?
According to Drew Conway, Alluvium:
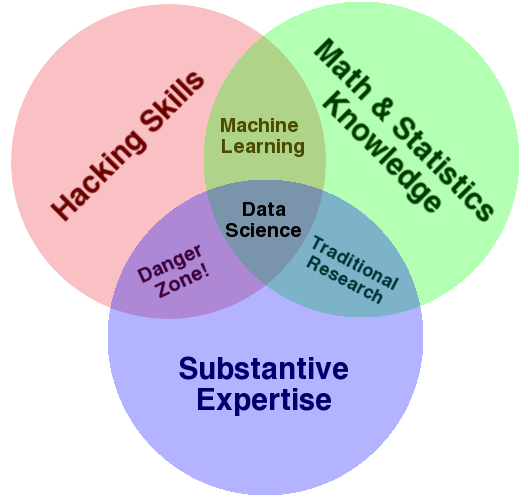
Data Science?
My definitions:
- Data Science
- You get some data. Then what do you do to get answers from it? Whatever that is, that's data science.
- Computational Data Science
- You get some data. You know how to program. Then what do you do?
Why Data Science?
Why is data science
so popular? Is it new?
There's more data being collected: web access logs, purchase history, click-through rates, location history, sensor data, ….
Sometimes the volume of data is big: too big to manage easily. That's where big data
starts.
Why Data Science?
People want answers/insights from that data: Is the marketing campaign working? Is the UI actually usable? What if we did X instead of Y?
New techniques: Machine learning lets us attack questions that were previously unanswerable. Computer scientists are realizing that statistics is important; statisticians are realizing that computer science is important.
Topics (1)
- Data science: what is it? How does data become useful?
- Data processing tools: Python + NumPy + Pandas; analysis tools in Python.
- Data aquisition. Or
where do we find data?
- Getting data into shape: cleaning; extract/transform/load.
Topics (2)
- Making sense of data: statistics. Or
it turns out that stats course was useful
. - Making sense of data: machine learning. Or
it's like AI, except it works
. - Data analysis strategies.
Topics (3)
- Big data tools: Apache Spark and a compute cluster.
- Data visualization and communicating results.