Noise Filtering
CMPT 353
Noise
Reality is noisy.
Whenever a value is measured, there will be some error introduced by the capture, transmission, etc.
Noise
In exercise 1, we saw code like this:
signal = np.sin(input_range) noise = np.random.normal(0, 0.15, N_SAMPLES) measurements = signal + noise
This is probably a good way to think of measured values:
\[ \mathit{measured\_value} = \mathit{true\_value} + \mathit{noise}\,. \]We want the true value, but get the noise too.
Noise
The result is that you get values that are (hopefully) close to reality, but not exactly.

We're generally interested in The Truth™.
Noise
There are several algorithms to help remove noise from a signal, and get as close to the truth as possible.
This is signal processing, and these are filtering algorithms.
Noise
Remember that the goal isn't to make a smooth curve. That's easy. e.g. with stats.linregress:

We're trying to uncover the true values with as little error as possible.
LOESS Smoothing
LOESS or LOWESS smoothing (LOcally WEighted Scatterplot Smoothing) is a technique to smooth a curve, thus removing the effects of noise.
LOESS Smoothing
The basic operation of LOESS:
- Take a local neighbourhood of the data.
- Fit a line (or higher-order polynomial) to that data. Pay more attention to the points in the middle of the neighbourhood (
weighting
). - Declare that line to be the part of the curve for the middle of the neighbourhood.
- Slide the window along, generating a curve as you go.
LOESS Smoothing
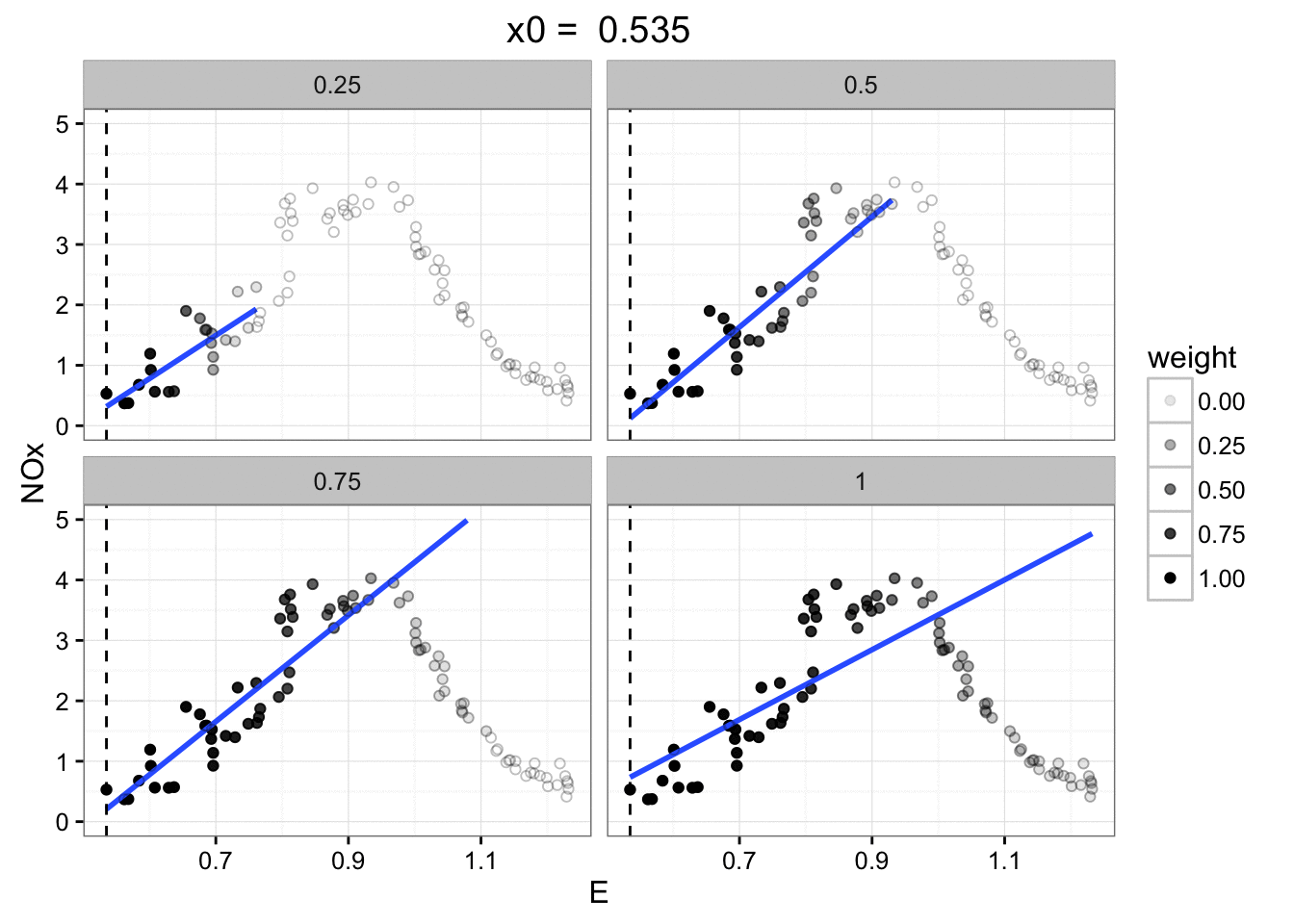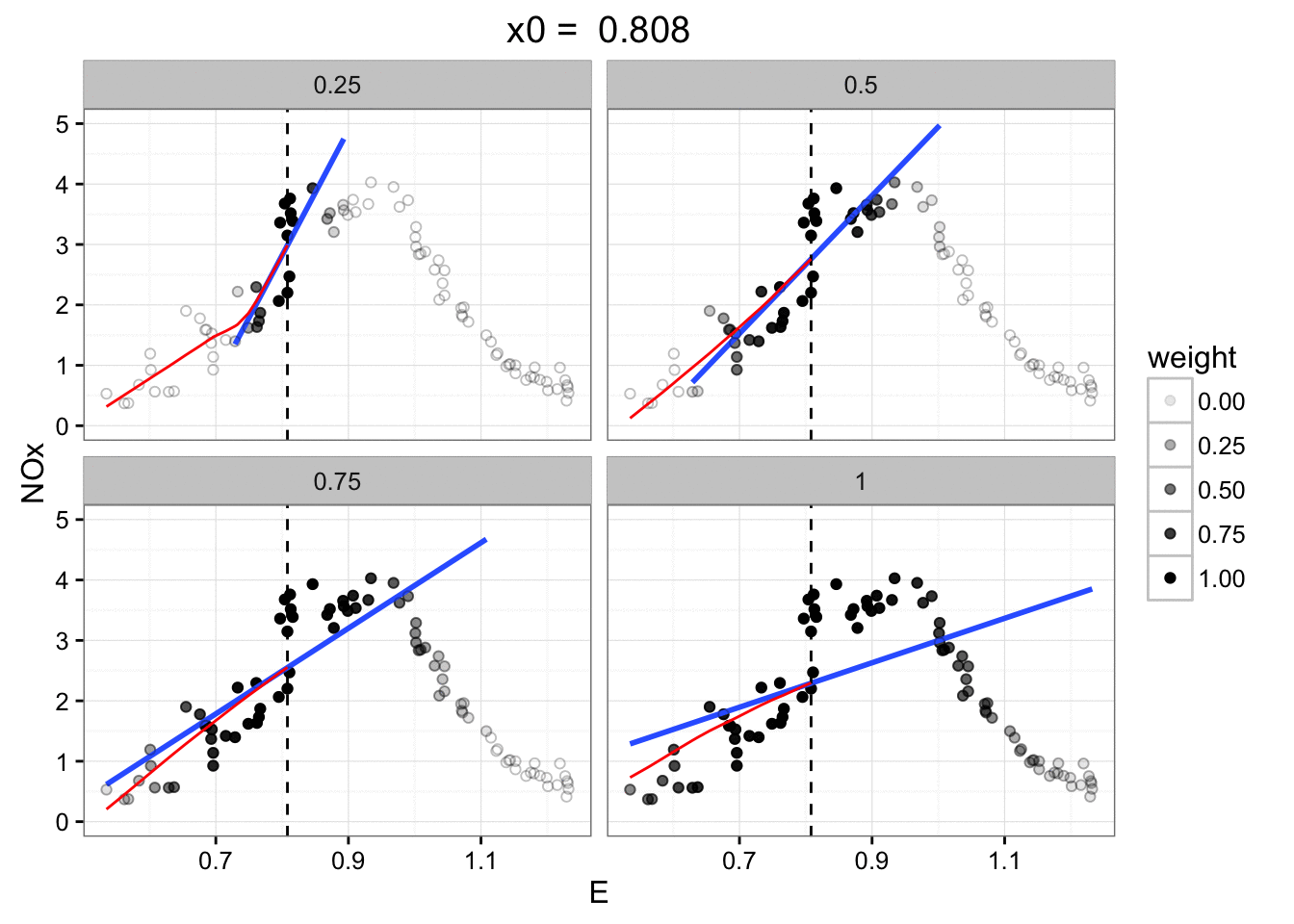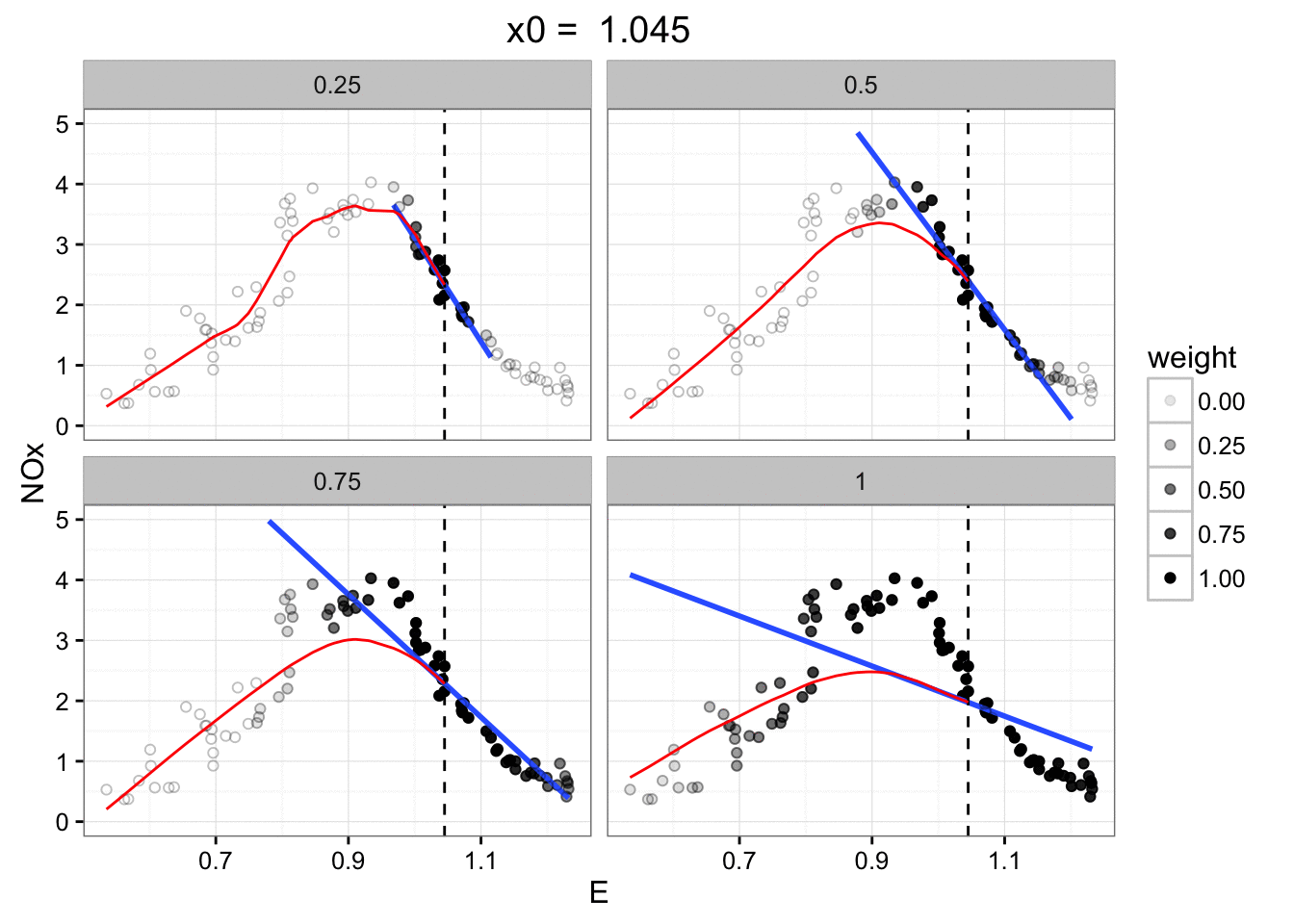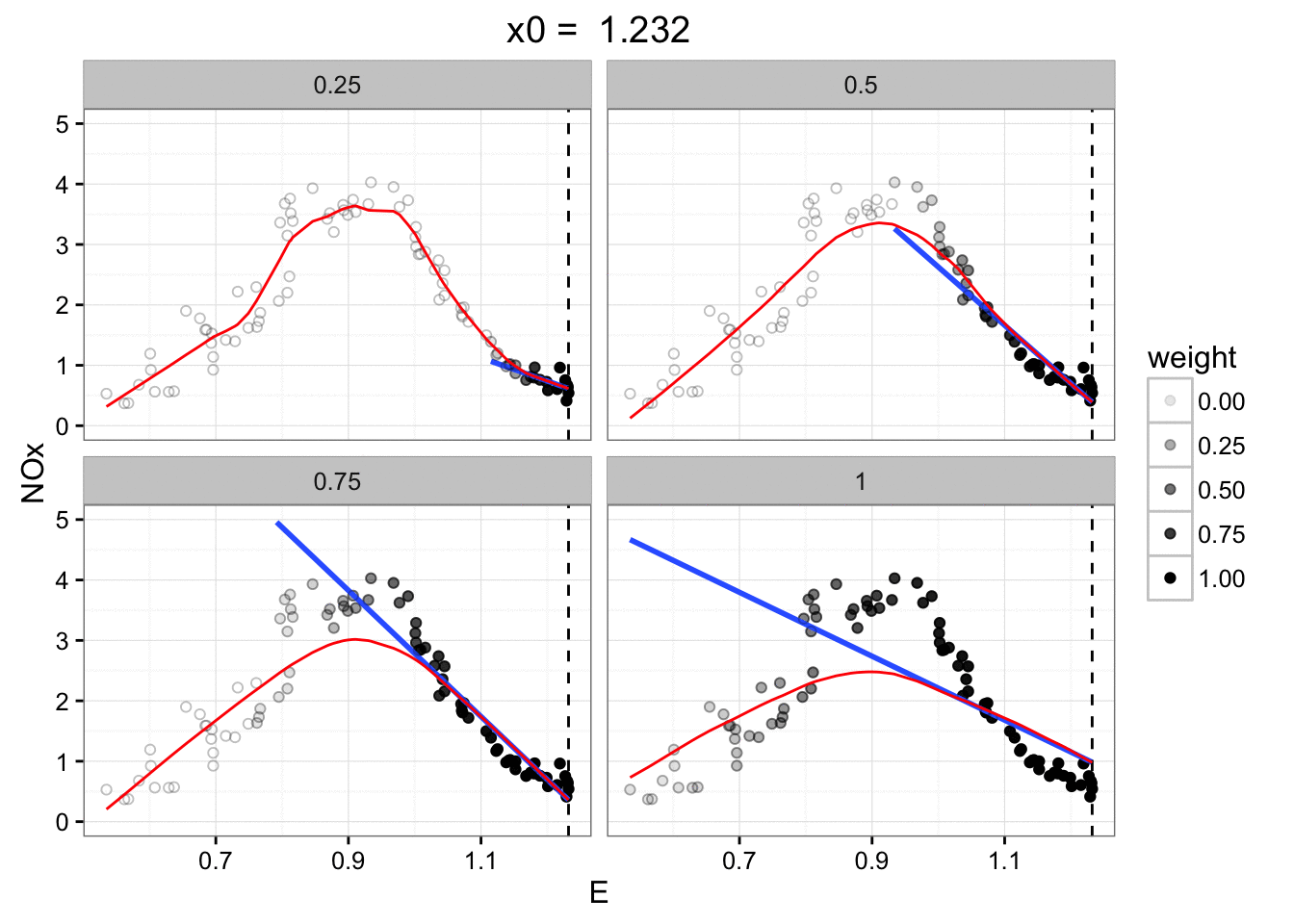
But that should really be animated: an animation of LOESS smoothing with different data fractions from Creating a LOESS animation with gganimate.
{kind=link}
LOESS Smoothing
The only decision we have to make is how big a local neighbourhood
we're going to look at for each local regression.
Small fraction: sensitive to noise in that small region.
Large fraction: won't respond as the signal changes.
LOESS Smoothing
On the sample data with different fractions:

LOESS Smoothing
LOESS is great if you have lots of samples. If your data is sparse, it doesn't have much to work with:

LOESS in Python
We saw in Exercise 1: there is a LOESS function in scipy:
from statsmodels.nonparametric.smoothers_lowess import lowess filtered = lowess(measurements, input_range, frac=0.05)
Note: parameters are \(y\) values then \(x\), unlike most functions. Returns a 2D array of \((x,y)\) values.
plt.plot(filtered[:, 0], filtered[:, 1], 'r-', linewidth=3)
LOESS in Python
tl;dr… LOESS smoothing is easy to work with: only one parameter to get right. It's better when it has lots of data to work with.
But it's about smoothing the curve, not exactly finding the true
signal. Those are often similar, but not always perfectly identical.
Kalman Filtering
You probably know more about your data than just the measurements. You know about the process that's creating them.
Kalman filtering is designed to let you express what you know. It predicts the most likely value for the truth
given your assumptions.
Kalman Filtering
You likely have some (incomplete) knowledge of how the data will be changing. You hopefully know:
- how much error is expected in measurements.
- how fast it changes.
- a prediction for the
next
value, given the current value. - how much error you expect on that prediction.
Probability Distributions
A refresher on probability distributions…
Distributions have a mean (or expected value) usually called \(\mu\).
… and a standard deviation, usually called \(\sigma\). The variance is \(\sigma^2\).
Probability Distributions
We are assuming here that our noise follows a normal distribution: it is Gaussian noise.
We hope \(\mu\) is the truth
(i.e. that there is no bias in the sensor). The \(\sigma\) says something about how much noise we're getting.
Probability Distributions
The range from \(\mu-\sigma\) to \(\mu+\sigma\) should contain around 68% of the observations.

{kind=link}
Probability Distributions
The covariance of two variables says something about how their values relate.
If the value of one is related to the other, they will have a non-zero covariance. Change in the same direction: positive covariance. Opposite direction: negative covariance.
Kalman Operation
A Kalman filter works with two things: our observations and our prediction of what we expect to happen (the prior). The difference between both of these and the truth are assumed to be normally distributed.
The filter the most likely true value given these distributions.
Kalman Operation
For example… We get a sensor reading of \(5.0\) and the sensor has \(\sigma=2.0\) (variance \(\sigma^2=4.0\)), then truth
should have this distribution:

Kalman Operation
We're also going to predict what the value will be, based on our knowledge of the world. Suppose we predicted \(x=8.0\) but are uncertain enough to say \(\sigma=5.0\) (\(\sigma^2=25.0\)). Then the world looks like:

Kalman Operation
The product
of these distributions gives our best guess about reality:

We predict the most likely outcome: the mean of the product distribution is 5.79.
Kalman Predictions
We're going to be observing several things about the world over time. At time step \(k\), call the true state \(\vec{x}_k\).
Kalman filtering asks us to predict the next state. We will call our estimate of the state \(\hat{x}_k\).
The big question: given (the filter's best guess for) \(\hat{x}_{k-1}\), what do you think \(\hat{x}_k\) will be?
Kalman Predictions
Suppose we have two values: position and velocity. Our values are \(\vec{x}_k = \left[\begin{smallmatrix} p_k \\ v_k \end{smallmatrix}\right]\).
Because we know how velocity works, we can predict the new position quite well. Our guess for the next velocity is less clear: we'll guess it doesn't change.
\[ \begin{align*} p_k &= p_{k-1} + \Delta t \cdot v_{k-1} \\ v_k &= v_{k-1} \\ \end{align*} \]Kalman Predictions
Or as a matrix operation,
\[ \begin{align*} \hat{x}_{k} &= \left[\begin{smallmatrix} p_k \\ v_k \end{smallmatrix}\right] = \left[\begin{smallmatrix} p_{k-1} + \Delta t \cdot v_{k-1} \\ v_{k-1} \end{smallmatrix}\right] \\ &= \left[\begin{smallmatrix} 1 & \Delta t \\ 0 & 1 \end{smallmatrix}\right] \left[\begin{smallmatrix} p_{k-1} \\ v_{k-1} \end{smallmatrix}\right] = \left[\begin{smallmatrix} 1 & \Delta t \\ 0 & 1 \end{smallmatrix}\right] \hat{x}_{k-1}\,. \end{align*} \]Kalman Predictions
Call that matrix the transition matrix, \(\mathbf{F}_k\). Our prediction will be
\[ \hat{x}_{k} = \mathbf{F}_k \hat{x}_{k-1} \,. \]In this example,
\[ \mathbf{F}_k = \left[\begin{smallmatrix} 1 & \Delta t \\ 0 & 1 \end{smallmatrix}\right] \,. \]The transition matrix lets us express \(\hat{x}_{k}\) as any linear combination of the values in \(\hat{x}_{k-1}\).
Kalman Predictions
The identity matrix \(\mathbf{F}_k = I_n\) predicts everything will stay the same
. Sometimes that's the best we can do. For three variables, that will be:
Kalman Predictions
e.g. If we predict first variable doubles; second variable is the sum of the two
, we get this prediction:
Which implies this transition matrix:
\[ \mathbf{F}_k = \left[\begin{smallmatrix} 2 & 0 \\ 1 & 1 \end{smallmatrix}\right] \]Kalman Variances
We need to give variance values for both our prediction and for our measurements.
Since we have multiple variables, we need to give variances for each, as well as covariances between each pair.
Kalman Variances
Variances are specified with (symmetric) \(n\times n\) matrices: entries are \(\Sigma_{jk}\), the covariance between variables \(j\) and \(k\) (\(\Sigma_{kk}\) is the variance of variable \(k\)).
e.g. three variables have \(\sigma\) (standard deviation) values 0.1, 0.2, 0.001; they are not correlated.
\[ \left[\begin{smallmatrix} 0.1^2 & 0 & 0 \\ 0 & 0.2^2 & 0 \\ 0 & 0 & 0.001^2 \end{smallmatrix}\right] \]Kalman Variances
We need these matricies for both the observations (measurements), often called \(\mathbf{R}\), and for our predictions, often \(\mathbf{Q}\).
Kalman Variances
The covariance matricies express our uncertainty in the measurements and predictions (relative to The Truth). i.e using
\[ \mathbf{R} = \left[\begin{smallmatrix} 0.3^2 & 0 \\ 0 & 0.9^2 \end{smallmatrix}\right] \]… says that we think our measurement for the first variable is usually
within 0.3 units of the true value. Or if this was the \(\mathbf{Q}\), that our prediction is usually
within 0.3 of the truth.
pykalman
As with everything else, there's a Python library for that. We'll use pykalman to do the arithmetic for us.
It's not included in SciPy or Anaconda: you'll need to install it with pip (or conda or pipenv or …).
You can download a notebook with Kalman example that follows…
Kalman Example
Let's make some noise(-y data):
n_samples = 25
input_range = np.linspace(0, 2*np.pi, n_samples,
dtype=np.float)
observations = pd.DataFrame()
observations['sin'] = (np.sin(input_range)
+ np.random.normal(0, 0.5, n_samples))
observations['cos'] = (np.cos(input_range)
+ np.random.normal(0, 0.25, n_samples))
Note the cheating: we know exactly the error on the measurements
because we added the noise explicitly.
Kalman Example
There's not much signal left:

Kalman Example
Aside: LOESS smoothing does surprisingly well, but still far from The Truth.

Kalman Example
We can tell a Kalman filter a bunch of stuff we know about the world.
We can do a good job guessing initial values (default is all-0) and we definitely know the covariance matrix.
from pykalman import KalmanFilter initial_value_guess = observations.iloc[0] observation_covariance = np.diag([0.5, 0.25]) ** 2
Guessed initial values: the first observations for each variable. Estimated sensor error: the values we know becase we saw the data being generated.
Kalman Example
And create the filter and use it…
kf = KalmanFilter(
initial_state_mean=initial_value_guess,
initial_state_covariance=observation_covariance,
observation_covariance=observation_covariance
)
pred_state, state_cov = kf.smooth(observations)
Kalman Example
The results are… disappointing.

Kalman Example
But, we haven't made any attempt to predict. We're accepting the defaults (everything stays the same; variance of 1; covariance 0), which aren't good for our problem.
Kalman Example
We know some trigonometry identities:
\[ \tfrac{d}{dx}\sin(x) = \cos(x) \\ \tfrac{d}{dx}\cos(x) = -\sin(x) \]… which imply that
\[ \sin(x + \Delta x) ≈ \sin(x) + \Delta x \cos(x) \\ \cos(x + \Delta x) ≈ \cos(x) - \Delta x \sin(x) \\ \]Kalman Example
Or expressed in matrix form:
\[ \left[\begin{smallmatrix} \sin(x + \Delta x) \\ \cos(x + \Delta x) \end{smallmatrix}\right] ≈ \left[\begin{smallmatrix} 1 & \Delta x \\ -\Delta x & 1 \end{smallmatrix}\right] \left[\begin{smallmatrix} \sin(x) \\ \cos(x) \end{smallmatrix}\right] \]Kalman Example
Since we know how things are changing, we can come up with a good transition matrix: \( \mathbf{F}_k = \left[\begin{smallmatrix} 1 & \Delta x \\ -\Delta x & 1\end{smallmatrix}\right] \)
delta_x = np.pi * 2 / n_samples transition_matrix = [[1, delta_x], [-delta_x, 1]]
Kalman Example
What's the standard deviation on those predictions? They're mathematical identities, so 0? Small?
transition_covariance = np.diag([0.2, 0.2]) ** 2
kf = KalmanFilter(
initial_state_mean=initial_value_guess,
initial_state_covariance=observation_covariance,
observation_covariance=observation_covariance,
transition_covariance=transition_covariance,
transition_matrices=transition_matrix
)
pred_state, state_cov = kf.smooth(observations)
Kalman Example
The results:

Kalman Example
To be fair: this is quite artificial. Being able to make a prediction with variance ≈0.0 isn't realistic.
In real-world data, a well-configured Kalman filter can still be astonishingly good.
Kalman Example
The problem? Getting all of the the parameters right.
# swapped negation on delta_x values... transition_matrix = [[1, -delta_x], [+delta_x, 1]]

Kalman Parameters
The \(\mathbf{F}_k\) or transition_matrix says what you predict the next value will be, based on the current value(s).
This is often a fairly bad prediction: if you could predict the outcome, why are we measuring anything? Still, we do our best and let it guide the results.
Kalman Parameters
The \(\mathbf{R}\) or observation_covariance matrix expresses what you think about the error in the observations.
Lower values → less sensor error assumed → observations have more effect on the result → more noise.
Higher values → ⋯ → less noise.
Kalman Parameters
The \(\mathbf{Q}\) or transition_covariance says what you think about the error in your prediction. Assuming the prediction is fairly smooth…
Lower values → less prediction error assumed → prediction has more effect on the result → less noise.
Higher values → ⋯ → more noise.
Kalman Parameters
In either case, my advice is:
- Unless you are sure about the covariances, leave them at 0: the covariance matricies will then be diagonal.
- Think of the
usual
amount of error you expect. How far off would the measurement/prediction have to be before you're surprised? That's \(\sigma\). Put \(\sigma^2\) in the covariance matrix.
Kalman Parameters
- Tweak the variances up/down to get a result you're happy with.
- If your measurement/prediction variances are extremely different (e.g. 50×), then you're essentially ignoring the high-variance value. Probably not what you want.
Kalman Parameters
There are several other paramaters to a Kalman filter that we haven't talked about: the gain (\(\mathbf{K}\)) and control inputs (\(\mathbf{B}_k\)).
It's also possible to make a less-constrained prediction with an unscented Kalman filter, where the prediction can be an arbitrary function (not just a matrix multiplication).
Kalman Summary
Kalman filtering is magical if you understand how the system works, and can get the parameters right.
LOESS is magical if you have a lot of samples: you don't have to figure out a lot of parameters and still get really good results.
Kalman Summary
If you have a lot of data and sane noise levels, LOESS is easier.

Kalman Summary
… but the Kalman filter may still be better.

Kalman Links
- How a Kalman filter works, in pictures
- Kalman and Bayesian Filters in Python, a book-length description of Kalman filters, as Jupyter Notebooks
- The Extended Kalman Filter: An Interactive Tutorial for Non-Experts
Other Filtering
There are many other filtering algorithms. They are generally based on keeping/removing frequencies you're interested in: that's particularly good if the signal you're interested in is somewhat periodic.
Other Filtering
Low-pass: keep the low frequencies; discard the high.
High-pass: keep the high frequencies; discard the low.
e.g. Suppose you're walking (∼1 Hz) and your phone vibrates (∼200 Hz) in your pocket. A low-pass filter would keep the signal from your walking; a high-pass filter would keep the phone vibration.
It depends what signal you're interested in.
Other Filtering
Random noise will add high frequency signals
to the sample: if we can get rid of exactly those, it'll be awesome.

Other Filtering
There are several filtering methods implemented in scipy.signal.
How do you choose between them? Good question. The Butterworth filter seems like a common choice, so let's try it…
Other Filtering
An order 3 Butterworth filter that keeps frequencies < 0.1 (i.e. > 10 samples/cycle) seems to get rid of all of the noise in this case.
from scipy import signal b, a = signal.butter(3, 0.1, btype='lowpass', analog=False) low_passed = signal.filtfilt(b, a, noisy_signal)

Other Filtering
If you keep frequencies too high, some of the noise will get through:

Other Filtering
If you filter too much, you can lose frequencies that are real signal:

For noise filtering, there's probably a fairly wide range of parameter values that give good results.
Other Filtering
Summary:
- Random noise will create high frequency
signal
. - You should have some idea what frequency range is
real
signal. - Butterworth and friends can keep a frequency range that's interesting to you.