Cloud & Data Management
Cloud & Data Management
Scalable Storage
We have seen a few ways to store data in a way that scales beyond the one computer
strawman.
Scalable Storage
With HDFS, we saw multiple computers in a cluster cooperate to store files.
A central NameNode coordinates many DataNodes. Each file (actually, block of a file) is replicated for both flexibility and fault tolerance.
Scale is essentially only limited by your budget for disks/computers.
Scalable Storage
We also saw Amazon S3 to store files.
We defer to AWS to provide the storage, reliability, scaling, etc. We imagine they can do that to a whatever scale we need.
Again, scale is limited primarily by our budget.
Scalable Storage
We will also soon look at scalable databases as a way to store lots of information (as records, not files).
Scalable Compute
When it comes to getting compute work done, we have also seen a few options.
We started with MapReduce: each job
consists of a map operation, then shuffle, then reduce (by key). An application can consist of many jobs run sequentially (although ours only had one each).
Scalable Compute
Then we saw Spark RDDs and DataFrames.
Both are more flexible and have their own strengths and weaknesses, but DataFrames are probably/usually/often the easiest to worth with and fastest.
MapReduce and Spark are certainly not the only options for compute at scale.
Scalable Compute
EMR offered many packages that could be installed (which are a mix of storage and compute tools).

Scalable Compute
Speaking of EMR, we have also seen two ways to manage compute work scheduling: YARN and EMR (which itself schedules our Spark jobs with YARN)
Scalable Compute
For both storage and compute, the message: if you need lots of it, you have to think about solutions that are more than one computer
.
The tools we have been working with help us get there.
Cloud Services
We have started to see the options of where these computers come from.
We could buy and install them on premises
. That's how our cluster is set up and it makes sense there: we need it available to you 24/7; there are privacy concerns about student work happening anywhere but on-campus; CMPT has the capacity available for a modest cluster.
Cloud Services
Or we could rent, as is possible with EMR.
That makes more sense if the capacity isn't needed all the time. It can also scale as needed, much beyond what our cluster could.
Cloud Services
Or for an even more managed approach, a higher-level data warehouse or data lake tool (we will see AWS Redshift and Spectrum) might make sense.
Basically, there's a tradeoff of control and upfront cost, with less management and per-unit cost.
Cloud Services
An analogy on the tradeoff of cloud computing: [*]
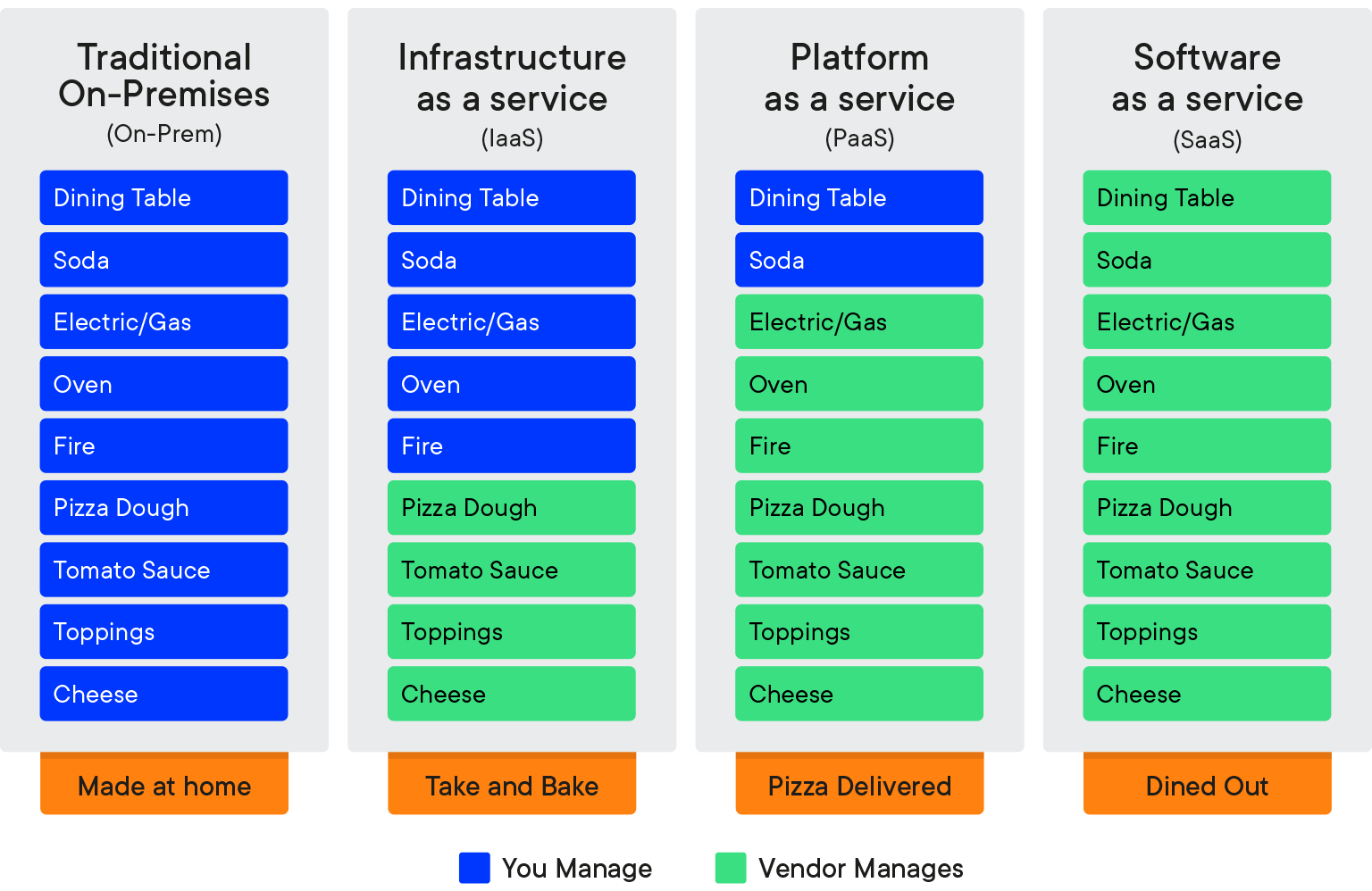
Cloud Services
Or with the actual computing concepts: [*]
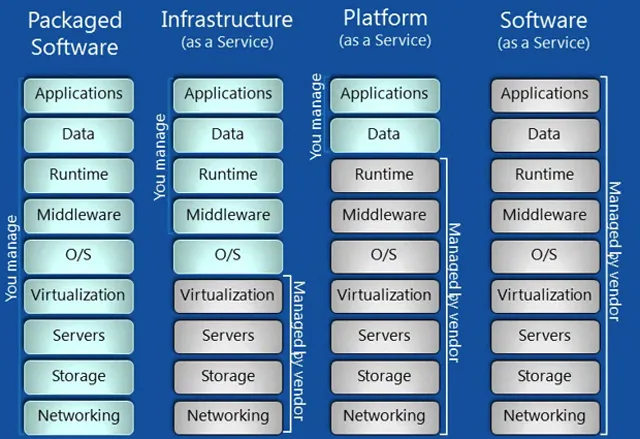
Cloud Services
The way you make the tradeoff here is going to depend on a lot of factors.
- Usage (e.g. 100% 24/7 vs monthly batch analysis).
- Need to scale.
- Budget: upfront vs operating.
- Regulatory compliance.
- 20 others I can't imagine.
Cloud Services
In assignments, we're moving between to the on-premises cluster to see a few more tools.
There's one more AWS assignment to look at data warehouse+lake tools.