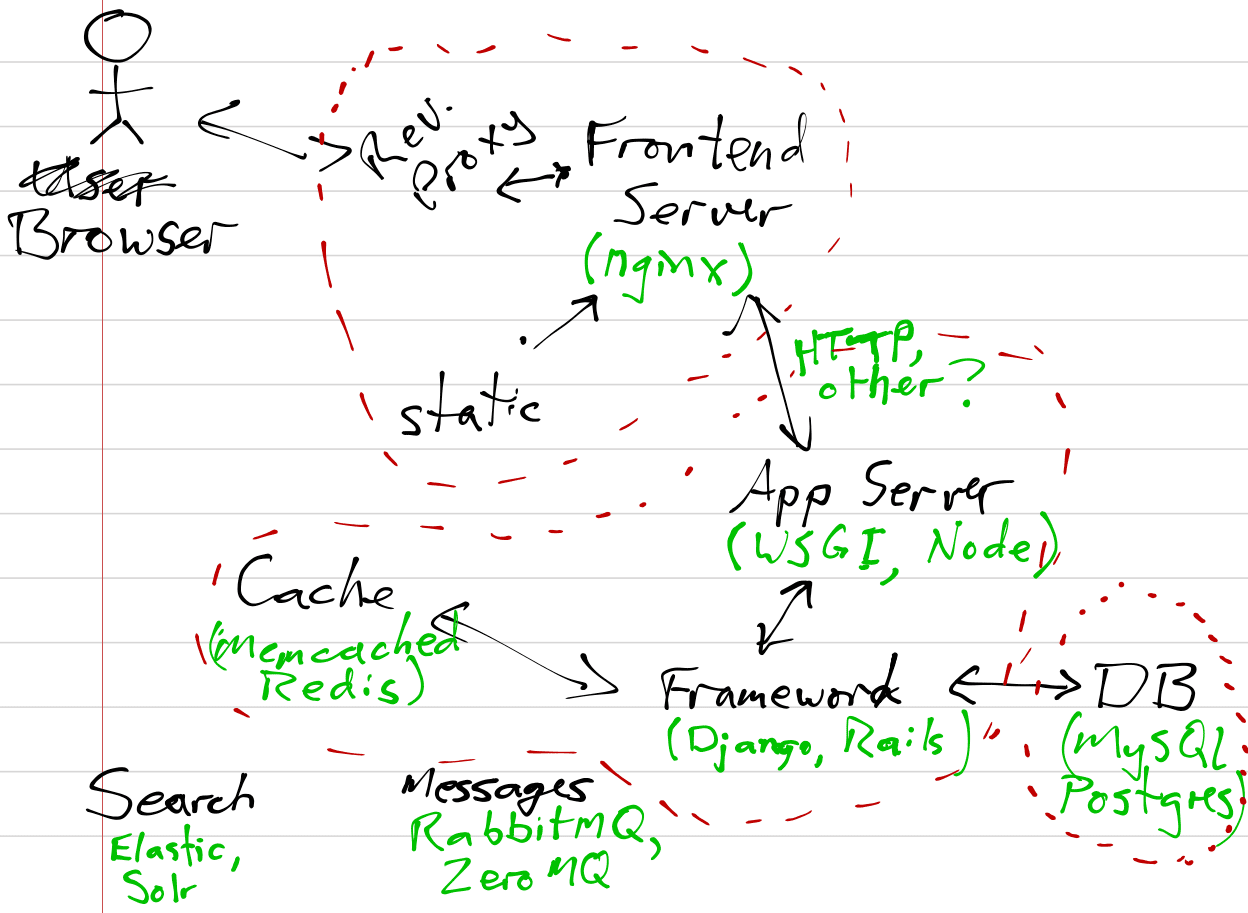
Server Architecture
Libraries and Frameworks
Roughly, “framework” = really big library that you use for just about everything in your project.
Libraries and Frameworks
Possible lessons from the technology evaluation:
- There are many commonly-encountered problems in web development.
- They have been solved already. Many times. With different levels of sanity.
- You don't have to solve these problems yourself.
Libraries and Frameworks
Some of the problems we have seen “solved”:
- Organizing your logic. (MVC and friends)
- Database data ↔ objects. (ORM)
- Mapping URLs to logic. (dispatch/routing)
- Creating HTML out of data you have. (templates)
- Synchronizing data client ↔ server. (APIs + JS ORM)
- Synchronizing data HTML display ↔ JS data structures. (data binding)
- Sessions and user authentication.
Libraries and Frameworks
Solving these problems (and thousands of others) again is likely a waste of time.
Being a productive programmer in the modern world requires you to be good at understanding existing solution: knowing when to look for one, being able to read and understand the docs, being able to read the source when the docs are incomplete.
You don't get enough practice at that.
Libraries and Frameworks
How do you choose a framework out of all of the options? Some questions to ask:
- Client-side or server-side? If client-side, what are you doing on the server to support it?
- Is it good at solving real problems that you have? Can you figure out the way it solves them?
- Can it solve problems besides the exact ones it was designed for?
- Are the obvious ways to do things secure? Do they produce nice code?
I wish I had a definitive answer.
Server Architecture
A good framework should make development fast, and make the site fast. For us, fast
means both throughput (many requests handled by one server) and latency (user doesn't wait long for a response).
Most obvious way to make things fast: don't do any more work than necessary to build a page.
Server Architecture
First step: get our code running.
We need to start with some way for a server to run our code to generate a response to a request. We want as little overhead in it as possible.
Server Architecture
There are standard APIs that let your code be called when a request comes in, and let it return a response.
Server Architecture
Each of these gives some structure that your code must implement. The promise is that you can then respond to HTTP requests.
Generally have a form like “create a method Controller.respond(request) that takes a Request object and returns a Response object.”
Server Architecture
Each of these has implementations that run your code, so a frontend web server (Nginx/Apache) can talk to them.
- Gunicorn, uWSGI for WSGI.
- Unicorn, Passenger for Rack.
- Node.js and Netty are the definitive implementation of their APIs.
- Tomcat, Jetty for Servlets.
Server Architecture
The architecture in these situations:
- User makes requests to a frontend server (like Nginx).
- Frontend server decides what to do: static resources from a file, dynamic requests forwarded to the…
- Backend server which runs application logic, communicates with frontend, starts up worker threads, etc.
Communication 2↔3 by HTTP or a custom protocol/socket.
Server Architecture
We have a bunch of parts working together:

Server Architecture
It's also possible for your logic to run in an interpreter integrated into the HTTP server. Most common with PHP in Apache, but can be done with others.
Apache may take the role of a backend server here. There may be another frontend server (maybe also Apache) doing static files, etc.
Server Architecture
Remember: whatever frontend framework/JavaScript stuff you have is just talking to your server by HTTP (or maybe WebSockets).
Many frontend frameworks obscure this by talking about two-way data binding
and Distributed Data Protocol
and MVVM architecture
.
It's all just a web server, HTTP(/WebSockets), browser, and JavaScript.
Architecture & Speed
We want to do as little work as possible to respond to a request. Less work = faster.
We keep the language interpreter/runtime environment alive so it doesn't have to be started when a request comes in.
Architecture & Speed
There might be other work necessary to create a response that you don't want to do with every request. e.g. connecting to the database server; inspecting the database structure; reading (and parsing and validating) config files; …
The architecture of the backend server should let you separate this.
Architecture & Speed
For example, Java Servlets have a very clear distinction:
public class ServletExample extends HttpServlet {
public void init() {
⋮ // connect to database; parse config file
}
protected void doGet(HttpServletRequest request,
HttpServletResponse response) {
⋮ // use config; make DB queries; produce response
}
public void destroy() {
⋮ // shutdown DB connection
}
}
doGet may be called many times on one instance.
Architecture & Speed
Python's WSGI has a similar but less explicit structure:
db_connection = …
config = …
def application(environ, start_response):
⋮
start_response('200 OK', response_headers)
return iterable_of_content_chunks
httpd = make_server('localhost', 8080, application)
httpd.serve_forever()
Architecture & Speed
There may be other work we can avoid when producing a response.
All of it if we can cache content in the user's browser and not get the request.
Most of it if we can send a 304 Not Modified.
Let's look for other places to avoid work…
Reverse Proxies
Also known as web accelerators, but that feels ambiguous.
The goal: use the concept of a caching proxy server, but make it much more effective…
Reverse Proxies
Even with a lot of optimization work, web apps can be slow.
- Dynamic languages (Python, Ruby, PHP, etc) tend to be slower.
- Lots of work to render templates, do ORM, etc.
- Can involve big DB queries, lengthy calculations.
Reverse Proxies
Remember the picture of a caching proxy?

Reverse Proxies
A reverse proxy has a similar role, but lives in your network:

{kind=link}
{kind=link}
{kind=link}
Reverse Proxies
The goal here is to do some HTTP caching, but to have all clients request through the cache.
This is achieved by naming the proxy cache example.com and making it behave like any other HTTP server to the outside world. The user has no idea what is happening behind the proxy.
Reverse Proxies
The reverse proxy can cache content for all users. That's a huge difference in load.
e.g. a Wikipedia page. Could set an expiry time 60 seconds in the future. Reverse proxy can cache it: backend only has to (do the expensive work to) generate the page once per minute.
Reverse Proxies
There are several tools to do this: Varnish; Squid; Nginx + memcached.
Likely will be merged with the frontend server
: most sites would have two things doing reverse proxy + external HTTP + static/dynamic decisions + application server calls + backend page generation.
Reverse Proxies
Since the cache is now within your network, stale cached data can be fixed. The proxy can allow a request from internal servers to prune cached data.
e.g. for Varnish:
PURGE /updated_page HTTP/1.0 Host: example.com
Reverse Proxies
Keeping consistent data in your cache isn't easy.
Option 1: Keep the cache times short and don't worry about it.
Option 2: Longer cache times, but purge from the cache whenever something would change a page.
There are only two hard things in Computer Science: cache invalidation and naming things. Phil Karlton
Reverse Proxies
There now will be many users hitting the same cache.
Good for performance, but what if users should see different content?
e.g. different Accept-language headers; different logged-in users.
Reverse Proxies
HTTP gives us the Vary header which the proxies will honour. e.g. if we have different translations:
Vary: accept-language
But varying by the user's cookie removes most of the benefits of the reverse proxy.
Vary: accept-language, cookie
Reverse Proxies
But again, we have more control over the cache when it's on our side.
e.g. Varnish has a configuration language to express how headers should be interpreted/cached.
Application-Level Caching
For truly dynamic content (i.e. every person sees a different page), a reverse proxy won't help much.
You can still use caching as part of your page-building logic: use a fast in-memory cache to store data so you can retrieve is quickly later.
Application-Level Caching
Likely candidates: Memcached, Redis.
Each of these give you somewhere that you can quickly store and retrieve data by key.
Application-Level Caching
As usual, your framework can probably help.
Some common use-cases for caching in a web app…
Application-Level Caching
Can cache a fragment of a rendered template, so it doesn't have to be built often. e.g. in Rails: *
<% @products.each do |product| %>
<% cache product do %>
<%= render product %>
<% end %>
<% end %>
Application-Level Caching
Can cache a controller/view response by arguments. e.g. in Express: *
var cache = require('apicache').middleware;
app.get('/api/collection/:id?',
cache('5 minutes'),
function(req, res) { … });
Or in Django:
@cache_page(120)
def view_collection(request, id):
…
Application-Level Caching
Or you will probably find a lower-level API that you can use as a programmer. e.g. Django
from django.core.cache import cache
def complicated_result(arg):
key = 'complicated_result-' + str(arg)
cached_result = cache.get(key)
if cached_result is not None:
return cached_result
else:
result = _build_complicated_result(arg)
cache.set(key, result, 120)
return result
def _build_complicated_result(arg)
⋮ # do the expensive calculations
Application-Level Caching
Again, having consistent data can be tricky.
All caches are effectively storing denormalized data: you need to give some thought to how to update every copy of a fact when necessary.
… or simply accept that the cache will sometimes be a little behind.
Application-Level Caching
Look for an opportunity to cache in your logic if you have:
- frequently-accessed, but infrequently-changing data.
- values that are difficult to calculate (lots of processor, many DB queries, etc).
- a good idea how long you can safely cache, or…
- a good idea when you need to invalidate cached data.
Multitier Architectures
After all that, we imagine a production site has a setup something like this: * * * *
{kind=link}
{kind=link}
{kind=link}

This is a three-tier architecture.
Multitier Architectures
We imagine each would be a separate computer with different specs. In our project, we're doing it all in one computer (VM or Docker host) for simplicity, but all of the ideas are there.
Multitier Architectures
All of the caching, optimization, and clever programming we imagine will eventually run out: the servers will eventually be unable to keep up with the load.
Multitier Architectures
The solution: replicate the roles. *
{kind=link}

We add a load balancer that can do the (easy) job of passing requests back and forth. Could also be the reverse proxy.
Multitier Architectures
The frontend and backend servers aren't storing anything, so it's trivial to have many identical copies. State is stored only in the DB.
Multitier Architectures
The replicated roles also give us redundancy.
If one web server fails (or needs to be rebooted or…) then the site won't go down, as long as the load balancer adapts.
Multitier Architectures
For stateless workers, multiple servers in one tier is easy.
We don't have a way to replicate the load balancer (yet).
For database servers, things are trickier.
Multitier Architectures
Multiple relational database servers coordinating and ensuring ACID is hard.
Can have read-only load balancing (if you have high read to write ratio).
Can have failover to a replica (for high availability).
Multitier Architectures
For a truly distributed database, you probably need to look for a NoSQL database, and choose which of the ACID/CAP things you're willing to give up.
Or to handle extra load, shard the data manually across many servers.
Honest advice: don't do this until you really need to, and understand the bottlenecks.
Multitier Architectures
It's easy to complicate the three-tier
picture further and have servers for many things like…
- HTTP for static files.
- sending email.
- logging/monitoring.
- log analysis/analytics/BI.
- asynchronous tasks.
- the other DB for some data.
- full text search.
- Memcached/Redis.
- ⋮
Multitier Architectures
The lesson: you can have as many servers as you can imagine. Complexity increases accordingly.
These could all be separate physical servers or VMs, or run on the same VM. Depends on your needs.
Tiers & Communication
As complexity of your infrastructure increases, it can become more difficult to coordinate the necessary work.
e.g. need to invalidate n cached pages because a user changed their profile; need to log many things to log server; need to update full-text index but that's slow; …
Some of these should be synchronous (i.e. completed before response is sent) but some can be asynchronous (i.e. done soon, but don't make the user wait).
Tiers & Communication
Need to sends messages between processes/servers? Consider a message broker.
The idea: some server has a message that must be processed: message broker receives it and ensures delivery. Another server listens for messages and handles them.
Notable examples: RabbitMQ, ZeroMQ, Kafka, Amazon SQS.
Tiers & Communication
These let you easily (and robustly) queue up work, and be sure it will happen eventually.
Useful for not-quite-synchronous tasks: logging user actions, updating full-text search, sending email.
Tiers & Communication
You can also use a task queue. Often built on a message broker, but gives you higher-level semantics.
Basically: you make a (modified) function call. A worker does it and sends the result back. You can wait for the result, or not.
e.g. Celery (Python), beanstalkd (Ruby), Kue (JavaScript).
Managing Servers
As your setup gets complicated, managing it can become more and more difficult. When replicating services, it's critical that they be configured identially.
Configuration management becomes more important for both consistency and documenting the setup.
Managing Servers
With configuration management (Chef or Docker or similar), it should be easy to…
- have a common config for all servers/containers.
- know the details of all configuration and how it has changed.
- deploy identically-configured servers/containers.
- update all servers/containers with security updates.
Managing Servers
We also have decisions to make about where each process lives.
e.g. are load balancing and reverse-proxy caching happening on the same hardware or not? Either is reasonable, depending on the load/usage. What if you want to move one?
Managing Servers
This leads to containers and Docker.
The idea: run your services in isolated lightweight containers. They are “smaller” than VMs, but more isolated than processes. Each container runs one “thing”.
e.g. a container for Nginx; another for Unicorn/Rails; another for PostgreSQL.
Managing Servers
Containers communicate only over network ports.
That prevents any shared state between them: all interactions should be well understood, which is a good idea. That lets you move them around without too much pain.
Docker Swarm, Kubernetes, Nomad can orchestrate
containers, deploying/restarting/moving them as necessary.
Managing Servers
But…
You still need to run the containers somewhere: you need a VM or server that's configured to run them. Then configure the containers.
The good architecture of only communicate by network
can be done without containers, if you're a little disciplined.
Cloud Hosting
Actually buying, powering, and replacing physical servers is even more of a pain. If you become more popular, you have to wait for hardware to scale up.
Solution: let somebody else buy and operate computers.
There is no cloud. It's just someone else's computer. Chris Watterston
Cloud Hosting
There are a few ways cloud services can be bought.
The usual categories…
Cloud Hosting
Software as a Service (SaaS): an application is provided.
e.g. Gmail email, Github for source control.
Cloud Hosting
Platform as a Service (PaaS): the provided platform can execute your logic, as long as you follow their rules.
e.g. Google App Engine, Amazon Lambda, MS Azure App services.
Cloud Hosting
Using PaaS is roughly: you write a function (for the prototype they specify), and connect it to an event (like an HTTP request to a particular path).
They make sure it runs somewhere. You accept the limitations of their environment and pay per call/CPU second.
But it's easy to lock yourself into their environment.
Cloud Hosting
Infrastructure as a Service (IaaS): you get VMs (or maybe containers) and configure them as you like. Provision/destroy VMs as needed.
e.g. Amazon EC2, Google Compute Engine, Digital Ocean.
Cloud Hosting
IaaS is probably what our project setup is simulating (at least the Vagrant/Chef option).
You still need to think about the VMs being ephemeral: the underlying hardware may fail. (The cloud doesn't prevent reality from existing.) Reliable storage is probably best done elsewhere.
Cloud Hosting
But…
- What about privacy laws? Who has access to your data, and are you legally prohibited from showing them?
- How locked in to the provider are you? What if they raise their prices and you want to move?
Content Delivery Networks
The planet is too big. Or the speed of light is too slow.
(circumference of earth)/(speed of light) = 134ms
A request/response around the planet will take at least that long. Intercontinental bandwidth isn't all you might hope for either.
Content Delivery Networks
That means that if you're serving a global audience, having server(s) in one location is likely a problem.
Content Delivery Networks
This isn't too hard to deal with for static content.
A content delivery network is basically a worldwide network of caching proxy servers. Users can contact the closest server and get the static resources from there.
e.g. Amazon CloudFront, Google Cloud CDN, Akamai.
Special purpose: CDNjs, Google Hosted Libraries.
Content Delivery Networks
The only trick needed is a slightly-smarter DNS server. It must give the user the IP address of the server that's “best” for them.
Content Delivery Networks
Distributing dynamic content is going to be harder.
- Could generate in one place, but have distributed reverse proxies.
- Could have a distributed database, and generate pages globally.
But most of the bytes on most pages are going to be static anyway.
Review
For better or worse, I drew this: